

Maximale Vorhersagequalität aus minimalen Daten | epicinsights
Setzt Google mit FLoC jetzt auf Fluide Personas?
Es war ein Paukenschlag für die digitale Werbewelt, als Google vor wenigen Wochen das Ende des personalisierten Werbetrackings in seiner jetzigen Form ankündigte. Bis zuletzt blieb zwar noch ein etwas zwiespältiges Gefühl haften, woher der selbstlose Sinneswandel auf Google´s Cashcow-Thema wohl kam. Immerhin machte Google die Ankündigung inmitten der 3rd-Party-Cookie-Enddebatte, während Apple und Facebook gerade richtig ins Werbetracking-Battle durchstarteten. Zusammen mit der Ende Januar ebenfalls von Google angekündigten Privacy Sandbox für Chrome und mit dem allgemeinen Privacy-First-Trends bei Browsern deutet vieles auf einen schneller werdenden Strukturwandel im Markt hin. Inwiefern dieser auch zu einer stärkeren Machtzentralisierung führt, bleibt zu beobachten.
Müssen Targeting- und Personalisierungsinstrumente zukünftig mit immer weniger Daten auskommen?
Bei stetig sinkender Datenvielfalt durch Tracking-Einschränkungen steigen gleichzeitig die Anforderungen der Kunden und Werbetreibenden in Sachen Zielgenauigkeit und KPI-Benchmarks. Wie kann das funktionieren?
Der Schlüssel steckt – wie so oft – in der algorithmischen Verwertung der Daten. Wie kann man die Auflösung der bestehenden Daten verbessern? Welche Methoden eignen sich dafür, aus einem minimalistischen Datenansatz maximale Vorhersagegenauigkeit zu ziehen? Diese Fragen beschäftigen uns seit 2015. Unsere Antwort: Fluide Personas.
Es wird also Zeit, sich die neuartige Cookie-Free-Personalisierungslösung von Google (FLoC) näher anzuschauen und mit unseren Fluiden Personas (FLuP?) zu vergleichen. Also: FloC vs. FLuP… Los geht’s:
Wie funktioniert FLoC?
FLoC heißt Googles System hinter dem neuen „Interest based advertising“ Konzept. FLoC bedeutet „Federated Learning of Cohorts“. Bisher wurden mittels Third-Party-Cookies alle Nutzer individuell auf Websites getrackt. Stark vereinfacht erklärt, wurden in der „alten Welt“ Herr Müller und Frau Maier also eins zu eins im Internet verfolgt. Mittels User-IDs wurden dabei ihre detaillierten Vorlieben und ihr Verhalten gespeichert. Die Tracking-Informationen wurden taxonomisch auf passende Werbetargetings gematcht. Wenn Herr Müller und Frau Maier also z.B. in der Zielgruppe der Werbetreibenden waren oder eine bestimmte Seite besucht hatten, bekamen sie eine entsprechende Anzeige ausgespielt, insofern die Tracking-ID passte.
Mit dem Federated Learning of Cohorts werden Nutzer auf Grund ihrer Eigenschaften und ihres Verhaltens auf Websites in Gruppen bzw. Kohorten eingeteilt. Dadurch sollen Einzelpersonen in der Menge verschwinden. Damit das gelingt, findet die sogenannte k-Anonymität Anwendung. Hierbei werden die Nutzer in so große Kohorten eingeteilt, bis keine Rückschlüsse mehr auf Einzelne möglich sind. Zum Schutz der User-Privatsphäre erfolgt die Verarbeitung der gesammelten Informationen geräteintern. Algorithmen auf dem Endgerät selbst weisen den Nutzer einer bestimmten Kohorte zu. Es wird also kein Cookie mehr generiert, der Daten des Users übermittelt. Laut Google haben Tests bereits gezeigt, dass Werbetreibende mit mindestens 95% der Conversions rechnen können, die sie bisher aus Third-Party-Cookies generiert haben. Mit verbesserter Datenlagen sollen sich die Ergebnisse weiter steigern.
Wie ähnlich sind sich FLoC und FLuP?
Der datenschutzkonforme Ansatz von Fluiden Personas, wie auch von Googles FLoC geht davon aus, dass es für Personalisierung prinzipiell unnötig ist, zu wissen, wer Herr Müller und Frau Maier eigentlich sind. Stattdessen wird nach Mustern und Ähnlichkeiten im Verhalten des gesamten Schwarms gesucht, zu denen ein Nutzer am ehesten passt, um daraus Prognosen für die Zielerreichung (z.B. Kauf) abzuleiten.
Das Individuum geht in der Gruppe auf
Ein User wird bei FLoC genau dem Schwarmverhalten bzw. dem segmentierten Cluster zugeordnet (Gruppen-IDs), das seinem Verhalten entspricht. Statt über seine individuelle Tracking-ID wird jeder User nachträglich über die Gruppen-ID werbeseitig adressierbar. Laut Google verschwindet der User damit aus Datenschutzperspektive im Schwarm von vielen. Spannend wird weiter zu beobachten sein, wie Google den Trade-off zwischen Anonymität und Individualität setzen wird (k-Anonymität). Denn hierbei verhalten sich die Faktoren Größe einer Gruppe und Grad der Individualisierung (der Anzeigen) gegensätzlich zueinander.
Bei Fluiden Personas und dem verbundenen Tracking gehen wir ähnlich vor
Bei Fluiden Personas als Grundlage für Content-Personalisierung von Websites läuft die Personalisierung ähnlich wie bei Google. Es werden Gruppen auf Basis der Zielerreichung gebildet (z.B. Nutzer, die ein bestimmtes Produkt gekauft haben). Bei der personalisierten Content-Ausspielung werden nur Parameter des Echtzeitverhaltens beobachtet und in Relation zu den zuvor trainierten Daten aus der Gruppe verglichen, die das Ziel (z.B. Conversion) ebenfalls erreicht haben. Die jeweiligen Gruppen (bzw. Segmente) werden dabei über rein algorithmisch festgelegte Eigenschaftssammlungen des Verhaltens definiert. Es wird also auf der Gruppe trainiert und die Ergebnisse der Vorhersagen pro Individuum ausgespielt, ohne dass es wichtig ist, wer das Individuum genau ist. Auch hier geht also der Einzelne in der Gruppe unter.
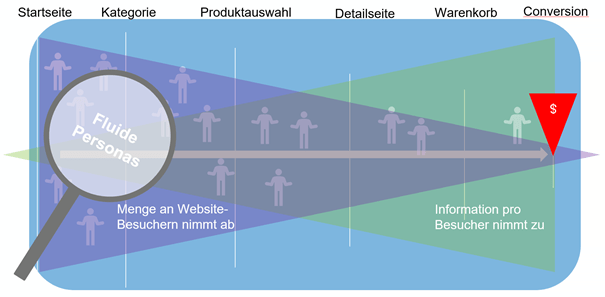
Statt einen Nutzer (auf Cookie-ID-Ebene) in der Tiefe zu analysieren und auf mehr oder weniger lückenhaften Datenfragmenten eins zu eins zu bearbeiten, werden alle „oberflächlichen“ (nicht personenbezogenen) Signale und Metadaten aller Nutzer als Trainingsgrundlage der Personalisierungs-KI genutzt. Da je nach Anonymisierungslevels für den Einsatz einer künstlichen Intelligenz ggf. nicht genug Daten vom Einzelnen vorhanden sind, bedient man sich der passenden Daten aus der ähnlichsten Gruppe. Die Anreicherung mit Schwarmdaten ist wichtig, denn ohne genug „Datenfutter“ können die Algorithmen nicht sauber arbeiten. Die Gruppierung selbst läuft nur im KI-Training, in welches alle anonymisierten Verhaltensdaten einfließen und welche nicht auf das Individuum zurückführbar sind. Bei Fluiden Personas erfolgt die Entscheidung und Ausspielung des Contents komplett browserseitig und in Echtzeit. Sie hinterlässt keine Datenspuren über den Moment der Ausspielung hinaus.
Der Nutzer bleibt 100% anonymisiert.
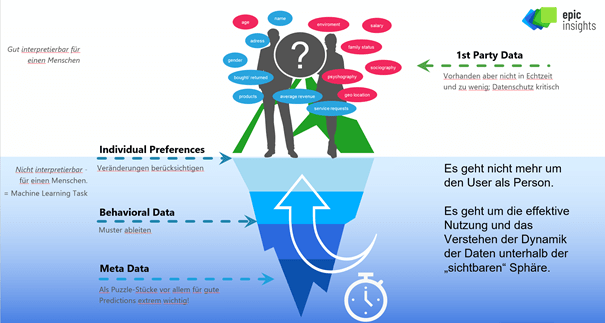
Eine weitere Säule, auf der die hohe Genauigkeit unserer Personalisierungs-KI baut, ist die Datenbasis selbst. Wir haben kein eigenes technisches Ökosystem, keinen eigenen Browser, mit Millionen von Nutzern. Unsere Kunden ebenfalls nicht. Das brauchen wir auch nicht, da wir für unsere Kunden nur im Mikrokosmos ihrer Markenwelt agieren und dort sinnvolle Daten aggregieren wollen. Daher werden für Fluide Personas getreu dem Motto „Werde Herr im eigenen Datenhaus“ Daten auf First-Party-Ebene generiert. Die Vorhersage-Algorithmen laufen auf den rohen Verhaltenseigenschaften, die auf Grundlage unserer einzigartigen Tracking-Engine deutlich mehr Daten auflösen, als es herkömmliche Tools leisten. Mit 200-facher Datenauflösung im Vergleich zu am Markt gängigen Lösungen gibt es hier nochmal ordentlich Datenboost für das Training der Künstlichen Intelligenz.
Das Konzept von Fluiden Personas und Google FLoC ist also tatsächlich sehr ähnlich, auch wenn es methodisch einige Unterschiede gibt. Im Vergleich zu Google arbeiten Fluide Personas quasi auf mikroskopischem Level (a.k.a. der Website oder dem Shop einer Marke). Die algorithmische Verarbeitung ist entsprechend granular. Google muss hier Faktor 1.000.000.000 größer ansetzen. Entsprechend sind die methodischen Ansätze hinter der Philosophie verschieden und technische Vergleiche sparen wir uns lieber komplett. Die Ergebnisse von FLoC sollen lt. Google mindestens genauso gut sein, wie die „alte“ Variante. Wir wissen, dass dieser datenschutzfreundliche Ansatz im Mikrokosmos „Website“ unserer Kunden sehr gut funktioniert. Wir sind daher guter Dinge, dass Google das entsprechend auch im Scale „Internet“ schafft.
Fazit: Eine personalisierte User Experience und Datenschutz schließen sich nicht aus
Die Personalisierungsphilosophie hinter FLuP und Googles FLoC verfolgt die gleichen Ansätze: Statt die einzelne Ameise auf dem Ameisenhaufen zu beobachten, blicken wir auf den gesamten Ameisenhaufen und versuchen Muster und Strukturen im Verhalten aller zu erkennen. Wenn ein einzelner User ein ähnliches Verhalten, wie das einer zuvor entdeckten Gruppen zeigt, werden hierüber die Zielerreichung des Individuums vorhergesagt und entsprechend passende Content-Angebote ausgespielt. Bei Fluiden Personas erfolgt dieser Abgleich mit jedem neuen, noch so kleinen Signal, das empfangen wird, während der User auf der Website surft.
Fakt ist: Personalisierung und Datenschutz sind vereinbar! Es muss Transparenz und Selbstwirksamkeit beim Nutzer hergestellt werden, darüber zu entscheiden, wie stark seine Interessen und die Vorteile eines personalisierten Angebots genutzt werden. Und es muss endlich ein Ende haben, Nutzer in statische Schubladen zu packen, aus denen es kein Entkommen gibt. Statt allein auf persönlichen Eigenschaften aufzusetzen, muss der Dynamik und Veränderlichkeit des digitalen Wesens Rechnung getragen werden. Denn: Einer guten Personalisierungsengine muss es egal sein, welches Geschlecht und Einkommen ein Nutzer hat. Der Brückenschlag zwischen Datenaggregation und Transparenz ist eine große Herausforderung, die es zu lösen gilt.
Bei FLoC sind aktuell noch viele technische und datenschutzseitige Fragen offen – besonders im Bereich Transparenz und Beeinflussbarkeit des Users selbst. Mit seinem technischen Ökosystem rund um Chrome und Android hat Google mit oder ohne FLoC, mit oder ohne Cookies, weitreichenden Zugriff auf alle Daten. Es bleibt spannend, wie sich die Entwicklungen fortsetzen, wie viel Machtverschiebung und Verdrängung der Strukturwandel für den Markt bedeuten werden. Und nicht zuletzt gilt zu beobachten, wie dieser Strukturwandel mittelfristig in der Mediawelt nachhallt und ob intelligente, unbürokratische Standards gefunden werden, die Nutzerinteressen und Werbeinteressen miteinander vereinen können.