

Data Science für eigene Wettbewerbsfähigkeit | epicinsights
Immer mehr Unternehmen erkennen die Wirkung, die Data Science auf ihre Wettbewerbsfähigkeit hat. Ein eigenes inhouse Data Team macht Data Science zu einem essenziellen Bestandteil der Unternehmensstrategie. Nach 5 Jahren am Markt sehen wir starke Trends zum Insourcing und plädieren absolut dafür. Data Science ist ein Inhouse-Thema!
Data Science und Machine Learning Teams müssen jedoch sehr gut in die Unternehmensstruktur und -kultur integriert werden, damit sie positive Wirkungen entfalten können. Die Gründung eines Data-Teams (oder einer „Data Unit“) und das richtige Stuffing sind an sich bereits große Herausforderungen – aber nur der erste Schritt.
Hier geben wir einen Überblick über verschiedene Integrationsmöglichkeiten einer Data Unit ins Unternehmen.
Dezentrale Data Science-Lösungen
Dezentralisiert arbeiten die einzelnen Datenexperten direkt in den verschiedenen Unternehmensabteilungen. Dazu kommt es vor allem dann, wenn sich die Nachfrage nach Data Science Expertise organisch entwickelt und über die Jahre hinweg vergrößert. Die Abteilungen bemerken ihren Bedarf an Datenanalyse und stellen entsprechendes Fachpersonal ein.
Ein Vorteil dieser Lösungen ist, dass die Data Scientists durch ihre Verankerung in einer Abteilung sehr nah am Tagesgeschehen und damit sensibler für die zu lösenden Probleme sind. Sollte es doch Rückfragen geben, ist zudem eine direkte und schnelle Abstimmung mit den Auftraggebern möglich.
Doch diese Modelle haben auch einige Nachteile. Die Zersplitterung der Data Scientists macht eine Standardisierung der Prozesse und Methoden fast unmöglich. Die einzelnen Datenwissenschaftler kommen zumeist nicht miteinander in Berührung. Das erschwert den Data Science-spezifischen Wissensaustausch und verhindert Synergieeffekte. Darunter leidet am Ende auch die Wettbewerbsfähigkeit, wenn wichtige Zusammenhänge und Verschränkungen unerkannt bleiben. Höhere Kosten für Tools und Infrastruktur sowie ein Effizienzverlust sind die Folgen.
Dezentrale Data Science-Lösungen eignen sich am besten für Unternehmen, die weniger Priorität auf data–driven setzen. Doch auch Unternehmen, die erst am Anfang der Integration von Data Science stehen, profitieren von diesen Lösungen. Auf dem Weg zur eigenen inhouse Data Unit sind dezentrale Lösungen zunächst kosten- und ressourcensparender.
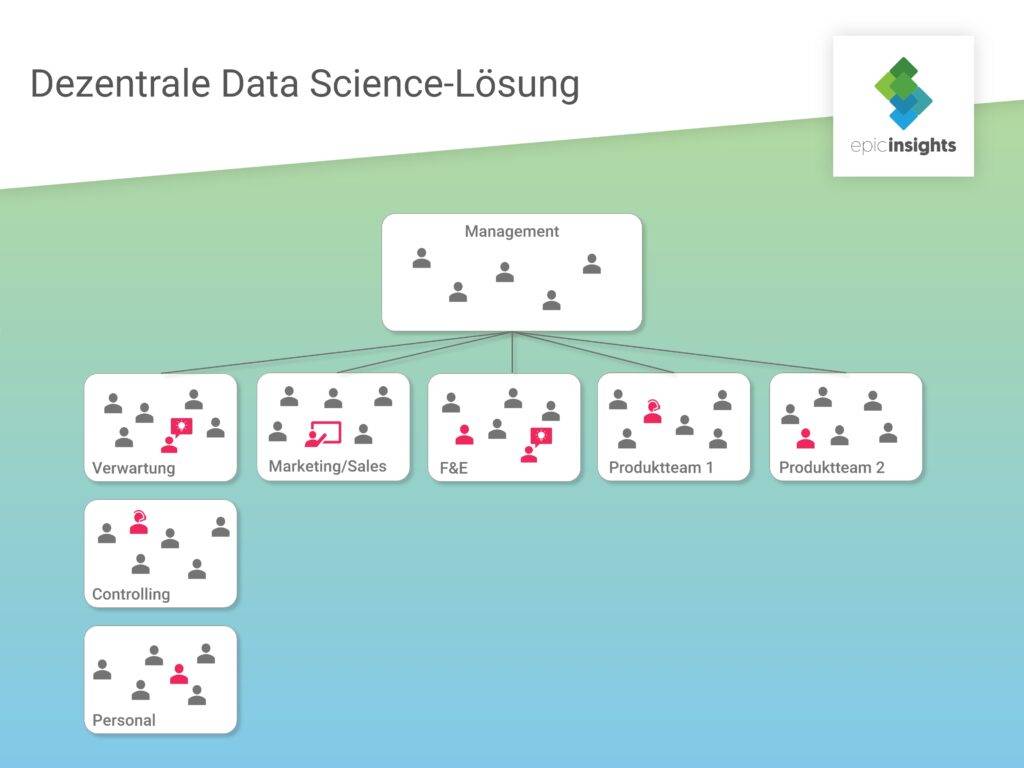
Embedded Model
Ein Beispiel für eine dezentralisierte Data Science Lösung ist das Embedded Model. Hierbei teilt sich das Data Science Team nach Bedarf auf unterschiedliche Abteilungen auf, je nach dem, wer ihre Arbeit gerade braucht. Die einzelnen Datenwissenschaftler berichten trotzdem an einen zentralen Head of Data Science. Sie können eine einheitliche Prozess- und Tech-Umgebung aufbauen und nutzen.
Vorteil dieses Modells ist bspw., dass in den einzelnen Abteilungen Datenexperten als Teil eines multidisziplinären Teams vor Ort sind und die Problemstellungen mit den Fachbereichen gemeinsam lösen. Zudem vereinfacht dieses Modell vor allem für kleinere Unternehmen den Managementaufwand, der bei einem zentralen Data Science Team anfallen würde.
Durch die ständige Zuweisung in verschiedene Abteilungen kann sich jedoch nur schwer ein Zugehörigkeitsgefühl aufbauen und der eigentliche Teamgedanke und der so wichtige und notwendige Austausch innerhalb des Data Teams geht verloren. Wegen der Dezentralisierung und Arbeit in den einzelnen Abteilungen werden Optimierungen außerdem nur lokal vorgenommen. Die Gefahr von Insellösungen und Silo-Anwendungen ist hoch. Einen langfristigen Mehrwert für das Unternehmen liefern jedoch eher globale Strategien und ganzheitlich gedachte Optimierungsprojekte.
Auch dieses Modell eignet sich eher für Unternehmen, die bei data driven Strategien am Anfang stehen. Es kann für als Vorstufe – quasi „Experimentierphase“ betrachtet werden, um Data Science langfristig als Kernelement zu verankern. Abteilungen werden schnell handlungsfähig, Mehrwerte können direkt evaluiert werden und das hilft dabei, die Unternehmenskultur auf „data driven“ ganzheitlich vorzubereiten.
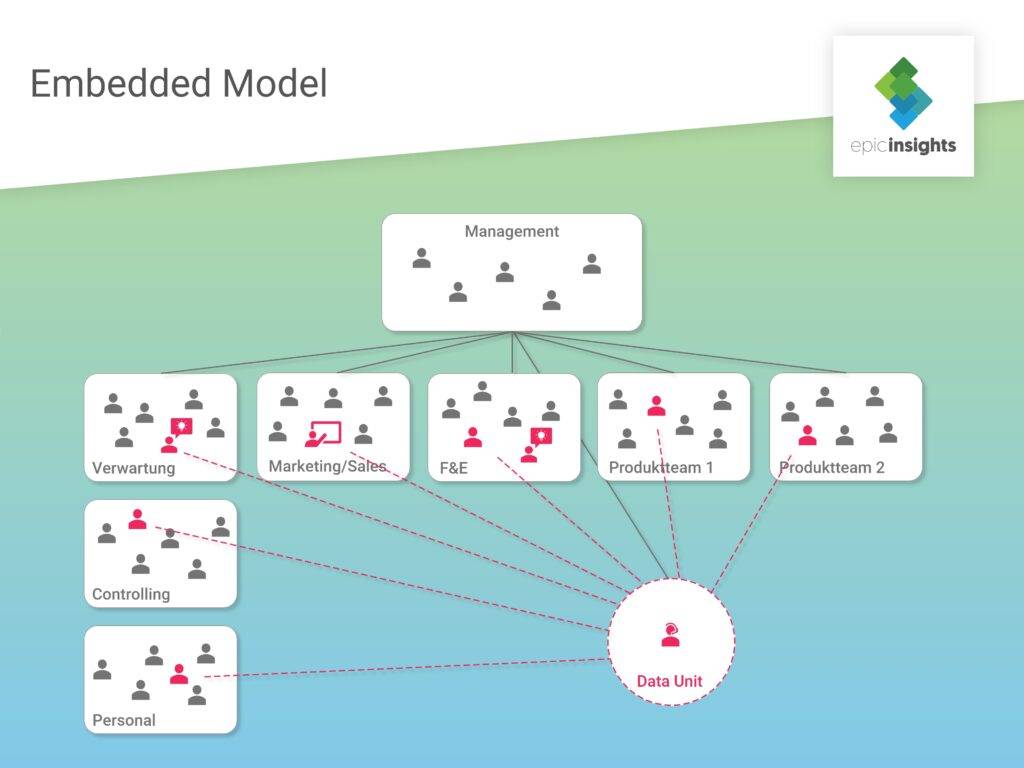
Zentrale Data Science-Lösungen
Hierbei ist ein Team an Data Scientists für alle im Unternehmen anfallenden Data Science Fragestellungen zuständig. So kommen sie mit den verschiedensten Projekten und Anforderungen in Berührung.
Vorteilhaft ist bei diesem Modell vor allem die Wissensbündelung an einem Ort. Durch den direkten Austausch der Datenwissenschaftler unter einander lässt sich die Fachkompetenz schneller ausbauen und Spezialisierungen vereinfachen. Zumeist ist auch der Teamleiter ein Experte in Sachen Data Science und damit in der Lage, die anfallenden Aufgaben effizient zu verteilen.
Ein sich daraus ergebender Nachteil ist jedoch die Isolationsgefahr des Data Teams vom Rest des Unternehmens. Die Datenwissenschaftler sind nicht direkt im Tagesgeschäft involviert und verlieren möglicherweise den Blick für das große Ganze. Zudem wird die Kommunikation mit anderen Abteilungen erschwert. Es dauert eine Weile, um Team und Infrastruktur lauffähig zu haben. Dafür muss sichergestellt werden, dass zwar ein notweniger Austausch mit Fachabteilungen stattfindet, aber operative Aufgaben des Tagesgeschäfts nicht die übergeordneten Ziele des Data Teams kannibalisieren.
Eine zentralisierte Data Unit eignet sich vor allem für große Unternehmen. Die diversen und riesig anfallenden Datenmengen (Stichwort: Big Data) erfordern stetig wachsende Analysen und dementsprechend auch ausgebildete Analysten. Der Mehrwert des zentralen Teams kann vor allem durch die Verbindung der Datentöpfe und die Betrachtung aus einer ganzheitlichen Perspektive geliefert werden. Wichtig bei dieser Lösung ist jedoch vor allem, die Analyse Funktion der Unit nicht zu einer Support Funktion für andere Abteilungen werden zu lassen.
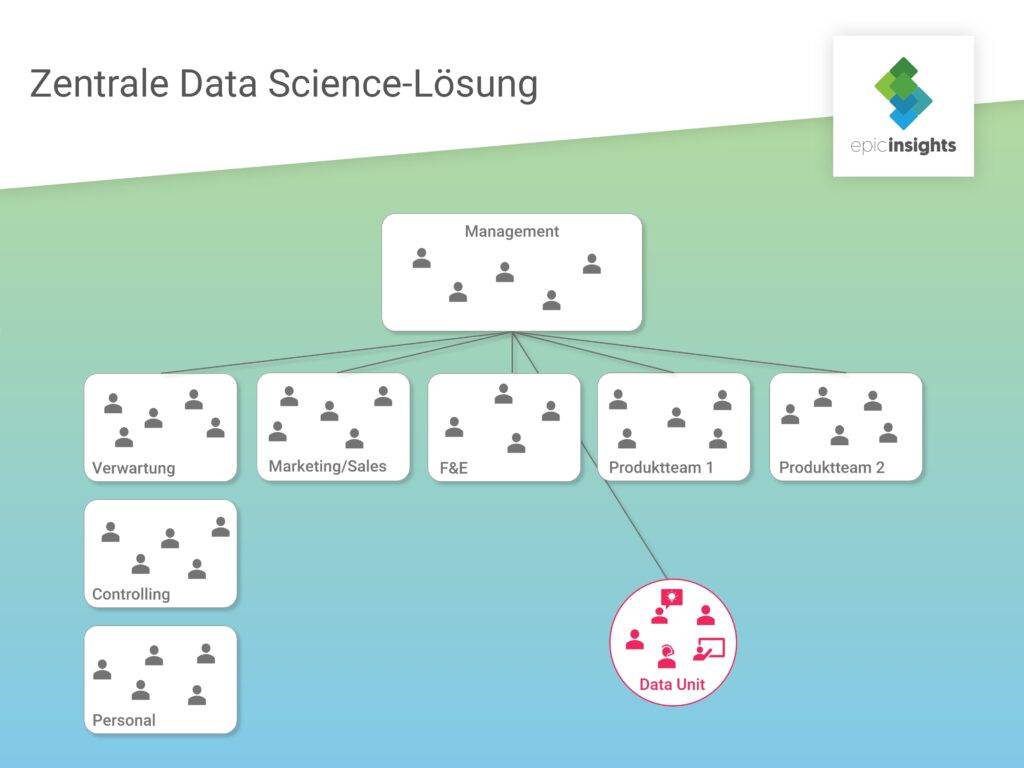
Center of Excellence Model
Ebenso zentralisiert ist das Data Science Team beim Center of Excellence Model (CoE) als eigene Abteilung angelegt. Die Erwartung hierbei ist, dass die Unit unabhängig vom Rest des Unternehmens arbeitet, um ungestört forschen zu können. Daher wird das Data Science Team auch als Innovationsschmiede des Unternehmens betrachtet. Ein dabei häufig auftretendes Problem ist, die Data Unit zu sehr vom Unternehmensalltag abzuschirmen. Die Datenwissenschaftler sind dadurch weder mit Infrastruktur noch Geschäftsmodell des Unternehmens vertraut und können so auch keine passenden Lösungen liefern.
Andererseits können sich durch die starke Zentralisierung dieses Modells die Data Science Teammitglieder vollkommen auf ihre Arbeit fokussieren und innovative Ideen entwickeln; was unter anderen Umständen nicht so einfach möglich ist. Das Center of Excellence Model ist zudem auf verschiedene andere Arten von Abteilungen oder Teams anwendbar. Für große Unternehmen ist bspw. ein eigenes KI Center of Excellence denkbar.
Wie bereits angemerkt, kann bei diesem Modell das fehlende Wissen über die Unternehmensprozesse ein Problem darstellen. Darüber hinaus ist es für KMU sehr kostenintensiv, ein solches Expertenteam von Grund auf aufzubauen; hier eignen sich vermutlich andere (dezentrale) Lösungen besser.
Erfahrungsgemäß erfolgt die Integration von Data Science in Unternehmen oftmals nach dem gleichen Ablauf. Zunächst kommen dezentrale Lösungen zum Einsatz. Wie bereits angemerkt, erfolgt diese Art der Integration durch die organisch steigende Nachfrage nach Data Science in den einzelnen Abteilungen. Ist dieser erste Schritt gemacht, schafft das Embedded Model eine Vorstufe zur alleinstehenden Data Unit. Die einzelnen Datenwissenschaftler sind zwar noch auf die Abteilungen verteilt, berichten aber an einen zentralen Head of Data Science. Ab hier ist es nicht mehr weit zur vollständigen Zentralisierung und eine eigenständige Data Unit nur der logische nächste Schritt.
Hybride Modelle
Neben den dezentralen und zentralen Modellen für die Integration eines Data Science Teams im Unternehmen gibt es auch Modelle, die sich keiner der beiden Arten eindeutig zuordnen lassen. Diese entstanden aus der Praxis heraus; die Unzulänglichkeiten der starren Modelle sollten ausgemerzt und ihre Vorteile wiederum gebündelt werden.
Democratic Model
Dieses Modell lässt jeden im Unternehmen zum Datenwissenschaftler werden; zumindest in der Theorie. Durch Business Intelligence Tools und übersichtliche Dashboards hat jeder Mitarbeiter die Möglichkeit, Unternehmensdaten in seine Arbeit mit einzubeziehen. Das Modell ist außerdem mit verschiedenen anderen kombinierbar, bspw. auch mit dem Center of Excellence Model.
Das entlastet die Datenwissenschaftler in ihrer Arbeit. Dadurch können sie sich auf größere Problemstellungen oder Optimierungen konzentrieren. Zudem ist die Investition in Infrastruktur und entsprechende Tools langfristig sehr lohnenswert. Angestellte werden in die Arbeit mit Daten einbezogen und entdecken den Mehrwert, der daraus entsteht.
Natürlich ist die Integration solcher Systeme nicht nur kosten-, sondern auch aufwandsintensiv, was sich nicht jedes Unternehmen leisten kann. Fraglich ist auch, ob die Anwendungen später im Tagesgeschäft überhaupt genutzt werden. Darüber hinaus sind diese Dashboards noch lange keine Datenwissenschaft, dafür sind sie viel zu unterkomplex. Wer also wirklich data driven werden will, braucht ein entsprechendes Expertenteam an seiner Seite.
Wie wäre es mit epicinsights? Wir sind langjähriger Berater für große und kleine Unternehmen rund die Themen Data Science und Künstliche Intelligenz. Wir realisieren wir für Sie maßgeschneiderte Data-Lösungen, Prozesse und unterstützen Sie auch beim Aufbau datenzentrierter inhouse Teams und Anwendungen.