


Natural Language Processing – Praxisguide
In den 2020ern bedeutet Data Literacy auch: Natural Language Processing kontextuell sinnvoll einsetzen und damit gegenüber den Wettbewerbern immer die Nase vorne zu haben. Statt einer allgemeinen Weiterbildung zum Thema Künstliche Intelligenz liefern wir Ihnen deshalb den typischen Einführungskurs Big Data und NLP im Kompaktformat.
Schnelleinstieg für NLP-Newbies:
Keyword-Alerts für Podcasts
Mit PodMon Alerts stellen wir Podcastinteressierten einen kostenlosen Alert-Dienst zur Verfügung.

Was ist Natural Language Processing überhaupt?
Natural Language Processing erfasst menschliche Sprache und verarbeitet sie durch trainierte Algorithmen weiter. Dies ist sowohl mit schriftlicher als auch mit mündlicher Sprache möglich. Ziel ist es, eine direkte Interaktion zwischen Mensch und Maschine mit Hilfe natürlicher Sprache zu ermöglichen.
Die Komplexität und Mehrdeutigkeit der menschlichen Sprache stellt hierbei die größte Schwierigkeit für den Computer dar. Es braucht ausgefeilte Algorithmen und Verfahren, um fehlerfreies Sprachverständnis anzutrainieren. Die Anwendungsbereiche von NLP sind dabei vielfältig:
- allgemeine Spracherkennung (text to speech & speech to text)
- Segmentierung der erfassten Sprache in Wörter, Phrasen und Sätze
- Funktionserkennung einzelner Wörter innerhalb eines Satzes (also Subjekt, Verb, Objekt usw.)
- Analyse der Zusammenhänge im Satz, Satzbeziehungen und Entitäten
NLP kommt darüber hinaus vor allem für Chatbots, Sprachassistenten, Übersetzungen sowie für Stimmungs- und Meinungsanalysen (Sentimentanalyse) zum Einsatz.
Natural Language Processing vs. Deep Learning
Häufig werden Natural Language Processing und das sogenannte Deep Learning miteinander verwechselt. Hier also eine Abgrenzung der beiden Begriffe:
NLP ist kurz zusammengefasst die Fähigkeit eines Programms, menschliche Sprache zu verstehen und je nach Zielsetzung zu verarbeiten. Dies geschieht mit Hilfe Künstlicher Intelligenz.
Deep Learning gehört dem Machine Learning an. Es basiert auf Künstlichen Neuronalen Netzwerken (KNN). Diese imitieren das menschliche Gehirn in seiner Funktion, Daten zu verarbeiten und Muster zu erkennen. Auf diesem Weg lernt der Computer durch Beispiele und ist in der Lage, darauf basierend Entscheidungen zu treffen.
NLP ist also das übergreifende (Forschungs-)Feld, in dem es um computerbasierte Verarbeitung von natürlicher Sprache geht. Deep Learning ist eine (von vielen) Methoden, die beim Natural Language Processing zum Einsatz kommt.
NLP, NLU und NLG
Natürliche Sprache kann durch Computer auf verschiedene Weise verarbeitet werden. Der Überbegriff dafür ist Natural Language Processing. Doch es gibt noch viele weitere Möglichkeiten des technischen Umgangs mit Sprache, die darunter zusammengefasst werden. Die Komplexität kann dabei stark variieren. Zwei davon sollen hier exemplarisch vorgestellt werden:
Natural Language Understanding (NLU) ist so eine komplexe Anwendung. Im Gegensatz zu NLP soll NLU die genaue Bedeutung eines Textes verstehen. Dazu benötigt es einen sogenannten Parser, der den Inhalt in ein geeignetes Format für die Weiterverarbeitung umwandelt. Zudem benötigt es ein umfangreiches Sprach- und Grammatiklexikon, auf das die Anwendung zugreifen kann. Darin müssen auch die verschiedenen Bedeutungen einzelner Wörter aufgelistet sein. Je detaillierter der Wortschatz, desto besser das Ergebnis des NLU.
Anders als NLP geht die Sprachverarbeitung von NLU weit über die Satzstruktur und ihre einzelnen Aspekte hinaus. NLU zielt vielmehr darauf ab, die Semantik und mögliche Mehrdeutigkeiten der natürlichen Sprache zu erkennen, also bspw. Ironie. Bis Computer aber in der Lage sind, menschliche Sprache auf diesem Level zu verstehen, wird es wohl noch eine Weile dauern.
Ein weiterer Teilbereich von Natural Language Processing ist Natural Language Generation (NLG). Dabei erstellt eine Software selbstständig „natürlich-sprachliche“ Texte. Input dafür sind strukturierte Daten, die in sekundenschnelle zu lesbaren Texten umgewandelt werden. Diese Automatisierung vereinfacht zum Beispiel die ansonsten sehr zeitintensiven Erstellungsprozess von Content enorm. Damit es jedoch gelingt, braucht es zunächst vordefinierte Vorlagen und Bedingungen zur Generierung menschlicher Sprache. Das sind beispielsweise vorformulierte Sätze, die durch Daten- und Lexikalisierungsalgorithmen je nach Kontext individualisiert werden.
Im Gegensatz zu NLP und NLU kann NLG natürliche Sprache zwar schreiben, jedoch weder lesen noch verstehen. Natural Language Processing und -Understanding analysieren menschliche Sprache und ziehen daraus Informationen. Natural Language Generation beginnt hingegen mit einer Reihe an Informationen in Form von Daten und kommuniziert diese in quasi natürlichsprachlichen Texten.
Themen-Trends aus der Podcast-Welt beyond Keywords!
PodMon Trends liefert neuartige Insights für Advertiser, Vermarkter und Creators, indem Themen aus allen Podcasts über große Zeiträume beleuchtet werden.

Wie schwierig ist die Verarbeitung natürlicher Sprache?
Die Schwierigkeit von NLP bildet die Datengrundlage an sich: Die menschliche Sprache ist komplex und folgt nicht immer logischen Regeln. Worte haben viele Varianten und Bedeutungen, die sich teilweise nur über den inhaltlichen Kontext erfassen lassen. So fällt es Programmen äußerst schwer, unterschwellige Bedeutungen in Texten zu erkennen. Deswegen ist es für die Software essentiell, eine umfangreiche strukturierte Datenbasis zu nutzen. Je mehr Daten vorliegen, desto besser arbeiten die Sprachmodelle bei der Erkennung von Mustern und Regeln.
Die Entwicklung und Weiterentwicklung von NLP – und den zugrundliegenden Prozessen – stellen vermutlich einige KMU vor eine Herausforderung. In fast allen Büros ersetzt die Digitalisierung mittlerweile Bücher und Papier durch Smartphones und Videokonferenzen. Dennoch sind die Early Adopter für Data Science-Anwendungen zumeist Unternehmen mit einem bestehenden digitalen Geschäftsmodell (z.B. E-Commerce). Diese Innovatoren verfügen schon jetzt über die nötige umfangreiche Daten- resp. Trainingsbasis und versprechen sich davon einen zuverlässigen und direkt messbaren ROI.
Deswegen scheinen die allermeisten Anwendungen für Language Processing derzeit vor allem im Onlinehandel und in kundennahen Prozessen zu funktionieren. Im Gemenge aus diversifizierten Datenströmen und hoher Anbieterkonkurrenz suchen jedoch immer mehr kleinere und mittlere Unternehmen Softwarelösungen, die ihnen intelligent unter die Arme greifen.
Software-Lösungen, welche die gesamte Wertschöpfung aus Data-Mining, Information Retrieval, Analytics und Inhaltserstellung zu einem funktionalen Framework integrieren, sind unglaublich komplex. Dafür benötigen Sie ein diverses Team aus Wissenschaftlern, Data Scientists und Data Engineers; welches zudem auf wichtige Bestandteile Ihrer Digitalstrategie einzahlen sollte.
Wie funktioniert Natural Language Processing in der Praxis?
Natural Language Processing ist ein KI-basierter Prozess, denn dabei verarbeiten Algorithmen große, zum Teil sich widersprechende Datenmengen. Wie bei allen Projekten, die Künstliche Intelligenz nutzen, gilt auch hier: One-Fits-All gibt es, entgegen vieler Mythen am Markt, (noch) nicht. Deshalb muss jeder Datenstrom für sich betrachtet werden.
Es gilt daher, Natural Language Processing schrittweise in die bestehende Prozesslandschaft zu integrieren. Am Besten bedienen Sie sich am kleinen Einmaleins des KI-Projektmanagements:
- Bestandsaufnahme und Data-Screening
- Zieldefinition und Konzeption
- Data Mining und Datenmodellierung
- Etablierung von Software-Prozessen und Infrastrukturen
- Validierung
Herausforderung Sprachkorpus
Wie bei allen Anwendungsfeldern von Künstlichen Intelligenz Systemen braucht es auch für Natural Language Processing genügend Trainingsdatensätze. Nur so kann erfolgreiches NLP funktionieren und weiter optimiert werden. Die dafür benötigten Sprachkorpora müssen dementsprechend zuverlässig sein, um die Maschine auf verschiedenste Themenfelder zu trainieren. Für allgemeine Themengebiete wie Kochen, Reisen oder das Wetter eignen sich besonders spezielle Wiki-Seiten oder sogar vorgefertigte Librarys. Je nach Sprache sind diese bereits mehr oder weniger gut vorhanden und bieten zusätzlich eine gute Grundlage für Erweiterungen.
Spezifischere Themen wie zum Beispiel im Industrie-Sektor, Rechts- und Gesetzestexte oder Technologie-Themen sind hingegen weniger gut dokumentiert und zusammengefasst. Daher ist es schwierig, in diesen Bereichen auf bestehende Daten aufzubauen. Die Zusammenstellung des geeigneten, individuellen Textkorpus wird dadurch je nach Anwendungsfall zum ausschlaggebenden Projektbestandteil.
Die neue Realität ist he|raus|for|dernd!
Aufgrund der fortschreitenden Vernetzung ist eine gezielte Steuerung von Informationsflüssen unabdingbar. Die Verarbeitung natürlicher Sprache ist ein Werkzeug dafür.
Der NLP Prozessablauf
Allgemein lässt sich auch der NLP Prozessablauf am CRISP-DM Modell veranschaulichen. Dieses dient eigentlich der Darstellung von Prozessen rund um Data Mining, lässt sich aber in diesem Fall leicht übertragen:
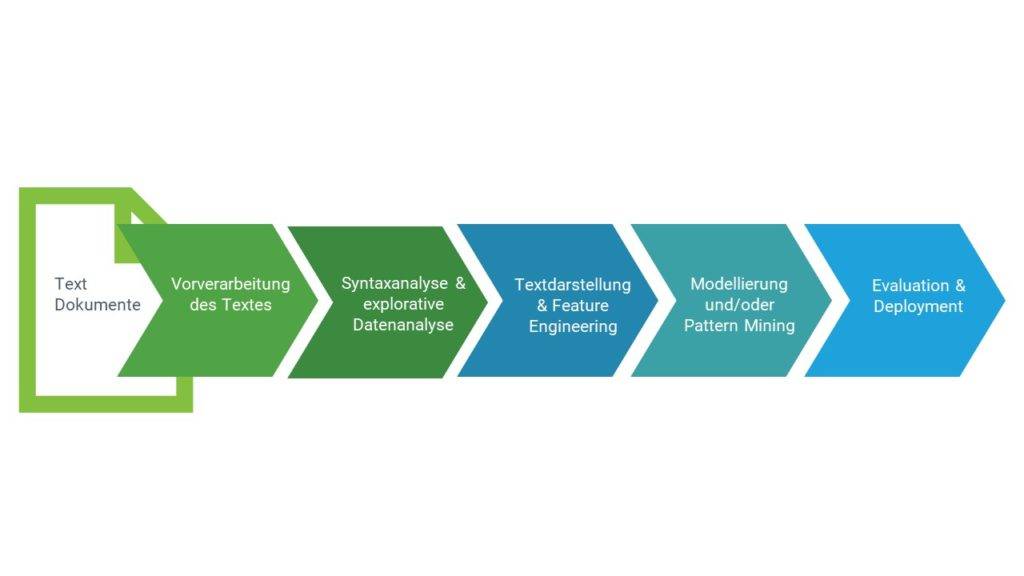
Im ersten Schritt müssen die Text Dokumente vorverarbeitet bzw. bereinigt werden. Da die Daten sowohl strukturiert als auch unstrukturiert vorliegen können, müssen sie zunächst dementsprechend sortiert und unter Umständen entfernt werden. Der relevante Text wird pro Satz in seine Einzelteile (z.B. Wörter oder Satzzeichen), sogenannte Tokens, zerlegt. Die Tokenisierung unterteilt die Sätze in einzelne Wörter bzw. Wortgruppen. Diese bleiben im Kontext der Sätze, um die Relationen zwischen ihnen zu erhalten. Die Tokens bekommen zudem Labels bzw. Annotationen zugewiesen, mit denen sie gruppiert werden können. Je nach Ziel der Sprachverarbeitung wird der Text darauffolgend strukturiert und analysiert. Hierfür werden bspw. Syntaxanalysen und explorative Datenanalysen durchgeführt. Der Text kann beispielhaft nach folgenden Elementen durchsucht und strukturiert werden:
- Subjekte bzw. Objekte, die im Text enthalten sind (bspw. Personen, Orte oder Tiere)
- Themen, die im Text angesprochen werden (werden durch Topic Modeling Techniken gruppiert)
- Stimmungsanalysen (sog. Sentiment Analysis) identifizieren Cue Words innerhalb des Textes, die auf die Gefühle des Verfassers hindeuten; also bspw. Wut, Trauer, Freude usw.
Der nächste Schritt ist die zielführende Analyse des strukturierten Textes. Dafür werden entweder überwachte oder unüberwachte Machine Learning Modelle verwendet; letztere legen den Fokus vor allem auf Mustererkennung und Gruppierung. Zuletzt werden die extrahierten Informationen in eine interpretierbare Form gebracht. Danach wird das verwendete Modell auf seinen Erfolg hin bewertet und für zukünftige Verwendung bereitgestellt.
NLP Modellierung ist abhängig von den Anwendungsfeldern
Je nach Anwendungsfeld der späteren Applikation gibt es im Bereich NLP eine Vielzahl von Ansätzen zur Datenmodellierung und dem Aufbau entsprechender Algorithmen. Die Anwendungsmöglichkeiten sind dabei weitreichend und divers. Sie reichen von analytischen Werkzeugen (z.B. Themen- und Meinungsanalysen, Content-Monitoring) bis hin zu autonomen Assistenten (z.B. Chatbots, Sprachassistenten, automatische Übersetzer). Durch die allgemeine Komplexität menschlicher Sprache und mögliche Software-Anwendungen im Speziellen bestehen NLP-basierte Applikationen aus mehreren Schichten und Kombinationen von Algorithmen und Data Processing Verfahren. Modellseitig wird im Allgemeinen zwischen unsupervised und supervised Methoden unterschieden. Drei der beliebtesten NLP-Algorithmen sind
- Keywords Extraction: Dieses Verfahren identifiziert und extrahiert die wichtigsten Wörter und Sätze eines Textes. Dies macht die Zusammenfassung, Organisation und Suche von Inhalten einfacher und effizienter.
- Named Entity Recognition: Mit dieser Technik werden Entitäten in unstrukturierten Texten gefunden und können Listen vordefinierter Kategorien zugeordnet werden wie Personen, Tiere usw. Die beiden zugrundeliegenden Prozesse sind daher Named Entity Identification und Named Entity Classification.
- Topic Modelling: Diese Anwendung erkennt abstrakte Themenkomplexe unter denen verschiedene Texte zusammengefasst werden können. Somit können Textkorpora nach Thema klassifiziert und organisiert werden.
Künstliche Intelligenz umfasst die ganze digitale Prozesskette
Natural Language Processing und dessen Integration in ein übergeordnetes KI-Framework können bereits vor der eigentlichen Data Science-Arbeit ins Stolpern geraten. Bevor R oder Python zum Einsatz kommen, gilt es, die Datenströme aus unterschiedlichen Quellen in eine Pipeline zu überführen: In welchem Format müssen die Daten vorliegen, damit Datenwissenschaftler mit ihnen arbeiten können? Wie stellen Sie eine kontinuierliche und stabile Datenversorgung sicher?
Damit die Ergebnisse Ihres Natural Language Processing-Vorhabens belastbar sind, ist oftmals ein großer Aufwand für die Vorbehandlung der Daten notwendig. Das Identifizieren und Löschen fehlender oder fehlerhafter Datenpunkte ist nur bedingt automatisierbar. Erst die wiederkehrende Projekterfahrung lehrt die bestmögliche Wahl der Waffen: Was sind die richtigen Mittel zur Dimensionsreduktion? Welcher Algorithmus passt zur Fragestellung? Mit welchen Metriken messe ich die Performance am besten?
Künstliche Intelligenz-Projekte: a piece of cake?
Zusammenfassend haben Sie nun bereits die ersten Stunden einer typischen Natural Language Processing-Weiterbildung hinter sich. Sie kennen die Grundlagen zu NLP und welche Prozesse sich dahinter verbergen. Zudem wissen Sie, dass Künstliche Intelligenz ohne ein erfahrenes Data Science-Team nur schwer umzusetzen ist; und dass dieses Team am besten im Rahme einer reflektierten Digitalstrategie agiert.
KI-basierte Audio-Suche und Medienbeobachtung
PodMon zeigt dir nicht nur via Jump-in-Points die sekundengenauen Stellen an, die für dich relevant sind, sondern auch die Stimmungslage rund um das entsprechende Keyword und alle Details zu den Podcast Shows.
Podcast Monitoring mit Natural Language Processing
Was mit NLP möglich ist, können wir Ihnen anhand eines unserer eigenen Projekte illustrieren: PodMon. PodMon ist ein KI-basiertes Podcast Monitoring Tool. Es ist in der Lage, tausende von Podcast-Episoden nach vorher festgelegten Keywords zu durchsuchen und diese via Email-Alert zu reporten. Dem Anwender dabei sogar konkrete Jump In-Points geliefert, die zur relevanten Stelle der Episode führen. Dank KI ist PodMon selbstlernend und wird mit jeder Suche besser. Innovative Speech-To-Text Modelle lassen PodMon auch neue Begriffe ohne Probleme erkennen und verstehen, anders als vergleichbare Podcast Monitoring Tools.