

Data Roles, same same but different? - epicinsights
Eine Google-Suche reicht aus, um auf schier endlose Jobbezeichnungen im Data Science Bereich a.k.a. Data Roles zu stoßen. Bei näherer Betrachtung wird deutlich: Es gibt weder einheitliche Definitionen dieser Tätigkeitsfelder noch lassen sie sich konkret voneinander abgrenzen. Um das zu verdeutlichen, stellen wir im Folgenden einige vor.
Diverse Anforderungsprofile: Data Roles
Für einen Datenmehrwert im Unternehmen braucht es sowohl die entsprechenden Data Skills als auch die jeweiligen Verantwortlichen für verschiedenste datenbezogene Aufgabenstellungen. Das Verknüpfen unterschiedlicher Infrastrukturkomponenten sowie die Bereinigung und Analyse der bestehenden Datenmengen wird erst durch das Zusammenspiel der verschiedenen Data Roles möglich.
Die Dynamik des Arbeitsmarkts, vor allem im Bereich Künstlicher Intelligenz, sorgt jedoch dafür, dass scheinbar täglich neue Jobs und Jobbezeichnungen aus dem Boden sprießen und eine trennscharfe Abgrenzung dieser gar nicht mehr so leichtfällt. Eine Methode, sich in diesem Dschungel zurechtzufinden, ist den Fokus mehr auf die Data Skills der einzelnen Akteure zu legen. Was wir damit meinen, sehen Sie hier:
In dieser Grafik lassen sich alle Data Roles entsprechend ihrer erforderlichen Skill Sets verorten. Um zu zeigen, wie nah einige dieser Data Roles beieinander liegen, folgen nun einige Beispiele:
Data Engineer
Der Dateningenieur oder auch ETL-Ingenieur (Extrahieren, Transformieren, Laden) ist in den Unternehmensdatenbanken und Verarbeitungssystemen zuhause. Hier kümmert er sich um die Dateninfrastruktur, baut Datenpipelines und stellt die komprimierten Daten für die weitere Verwertung zur Verfügung.
Wenn Sie einen tiefergehenden Einblick in die Arbeit des Data Engineers erhalten wollen, dann klicken Sie hier.
Machine Learning Operations
Machine Learning Operations (kurz MLOps) sorgen für reibungslose Abläufe innerhalb des ML-Entwicklungsprozesses. ML-Operator stellen sicher, dass alle benötigten Tools zur Verfügung stehen, die Infrastruktur und Umgebungen zugänglich sind. Damit sorgen sie auch für die reibungslose Zusammenarbeit und Kommunikation zwischen Datenwissenschaftlern und IT-Spezialisten bei der Umsetzung und Automatisierung von ML-Algorithmen.
ML-Operator stellen sicher, dass der ML-Lebenszyklus effizient, gut dokumentiert und mögliche Probleme einfach zu beheben sind. Die Anforderungen, die sie an Machine Learning stellen sind Reproduzierbarkeit, Kollaboration, Skalierbarkeit und Kontinuität. Ihre Arbeit ist dadurch mit Development Operations (DevOps) vergleichbar, jedoch konkret auf die Anforderungen von Machine Learning zugeschnitten.
Data Scientist
Neben Big Data ist Data Science wohl DAS Buzzword der letzten Jahre. Doch viele Unternehmen und Entscheider überschätzen die Kernaufgaben eines Data Scientists wahrscheinlich noch. Natürlich kann diese Stelle mit einem wahren Allrounder besetzt werden, aber das sagenumwobene Data Unicorn gibt es (leider?) trotzdem nicht.
Zum Aufgabenbereich des Data Scientists gehören bspw. die Auswahl der passenden Methoden, die Entwicklung von Vorhersagemodellen oder auch die Optimierung von Neuronalen Netzen. Mit Hilfe dieser lassen sich zukünftige Ereignisse vorhersagen und dementsprechend Entscheidungen treffen. Data Scientists sorgen also dafür, den größtmöglichen Nutzen aus den verfügbaren Unternehmensdaten zu ziehen.
Auf einem umkämpften Bewerbermarkt sind Datenwissenschaftler ein begehrtes Gut. Effektive Data Scientists sind geübt im Zusammenspiel mit Backend- und Frontend-Entwicklern, kennen agile Arbeitsmethoden und aktualisieren stetig ihren Methodenkoffer.
Data Analyst
Der Data Analyst leistet vergleichbare Arbeit wie der Data Scientist. Er behält die Unternehmensdaten stets im Blick, um schnellstmöglich Auffälligkeiten darin zu identifizieren und darauf reagieren zu können. Zudem bereinigt der Data Analyst die Daten, analysiert sie (obviously), führt Testläufe durch und leitet seine Ergebnisse an andere Unternehmensstellen weiter.
Die genaue Unterscheidung von Data Analyst und Data Scientist ist gar nicht so leicht. Ein Unterschied zwischen den beiden Data Jobformen ist aber bspw., dass der Datenanalyst geschäftskritische Fragestellungen von anderen Abteilungen (z.B. Marketing) entgegennimmt und nach einer Lösung dafür sucht. Der Data Scientist hingegen formuliert Fragestellungen an einen Datensatz in der Regel selbst.
Statistician
Der Statistiker sorgt mit Fachwissen aus der Mathematik für eine andere Perspektive auf die Daten. Dadurch kann er bspw. bestimmen, welche Methode der Datenerfassung sich für einen bestimmten Zweck am besten eignet. Mit seiner logischen Denkweise sammelt er die Daten, wandelt sie in Informationen um und liefert daraus nützliche Erkenntnisse. Zudem liegt ihm auch die Entwicklung analytischer Modelle und mathematischer Algorithmen.
Die besondere Datenkompetenz des Statistikers sorgt vor allem dafür, voreilige Schlüsse über die Daten bzw. den Datensatz zu verhindern. Nur weil bspw. eine Machine Learning Methode in einem Data Set funktioniert hat, lässt sich dies nicht automatisch auch auf andere übertragen. Statistiker helfen so Entscheidern, über die analysierten Daten hinaus zu sinnvollen Schlussfolgerungen zu kommen.
Business Analyst
Die Rolle des Business Analysts unterscheidet sich wohl am meisten von den hier bisher aufgeführten. Im Gegensatz zu den anderen Data Roles hat er weniger tiefgreifendes Technikwissen, dafür aber umso mehr Verständnis für die verschiedenen Unternehmensprozesse.
Der Business Analyst verwandelt die gefundenen Data Insights in umsetzbare Business Strategien, um das Unternehmen weiter voranzubringen. Das macht ihn zum Sprachrohr zwischen Data Unit und Entscheidungsträgern. Als Industrie-Insider erkennt er zudem die wichtigsten Trends und hält die kosteneffektivsten Lösungen für das Unternehmen bereit.
Kommen wir also zurück zur vorgestellten Grafik und schauen uns an, wo sich die einzelnen Data Roles dort verorten lassen:
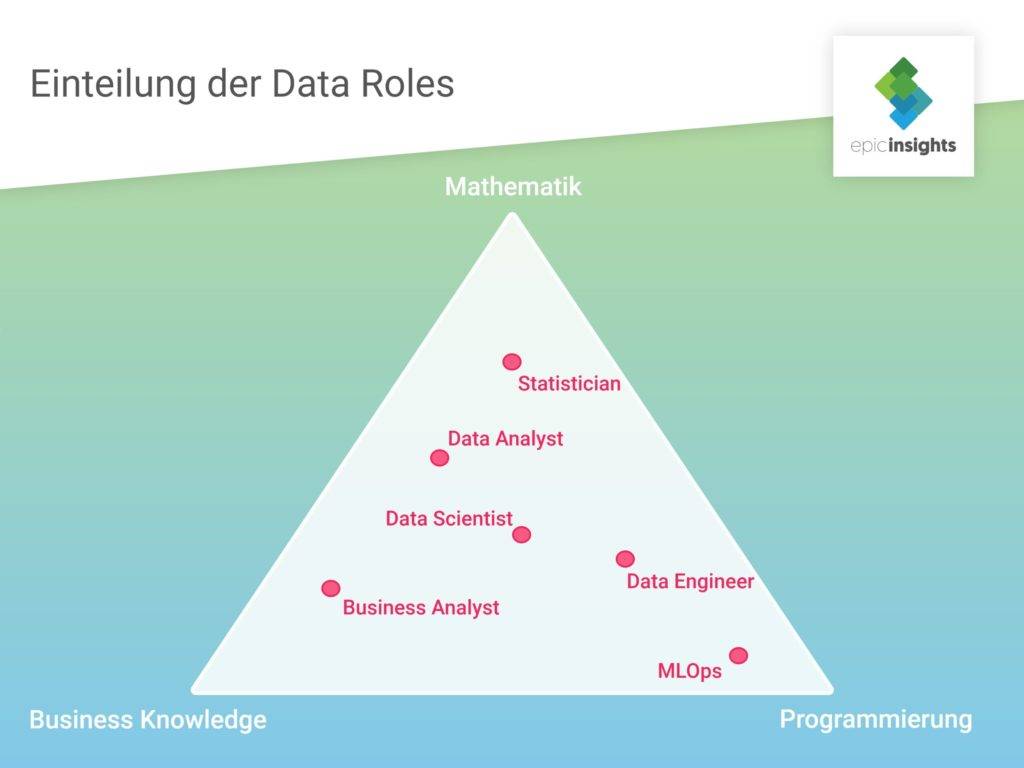
Hier wird ersichtlich, wie nah die einzelnen Rollen in ihren Skill Sets beieinander liegen. Bereits bei der Beschreibung wurde deutlich, dass sich bspw. die Aufgabenbereiche von Data Scientist und Data Analyst stark ähneln. In der Grafik wird diese Similarität noch einmal mehr als deutlich.
Die Zusammenstellung des Teams
Bei der Zusammensetzung des Data Science Teams spielen vor allem die Unternehmensgröße und die umzusetzenden Ziele eine entscheidende Rolle. Sicher ist es bspw. für ein kleineres Unternehmen mit überschaubaren Ressourcen nicht sinnvoll (und vor allem nicht nötig), eine Vielzahl an Data Roles besetzen zu wollen.
Vielmehr sollte anfangs darauf geachtet werden, eher weniger Personal, dafür aber mit einem breiten Kompetenzspektrum, einzustellen; also mit breiteren Data Skills. Wächst das Unternehmen und damit auch Budget und Anforderungen an das Data Team, kann der Fokus auf einen größeren Ausbau der einzelnen Data Roles gelegt und eine stärkere Spezialisierung der einzelnen Mitglieder angestrebt werden.
Zentraler oder dezentraler Aufbau?
Für viele Unternehmen stellt sich weiterhin die Frage, ob ein zentrales oder dezentrales Data Science Team sinnvoller ist. Die zentrale Lösung steht für die Bündelung der einzelnen Team Mitglieder an einem Ort, ein sogenanntes Data Science Competence Center. Dezentral hingegen sind einzelne Data Scientists o. ä. in den verschiedenen Fachabteilungen eingesetzt. Auch hier müssen vor allem die Unternehmensgröße und die individuelle Data-Strategie des Unternehmens beachtet werden.
Möchten Sie auch ein eigenes Data Science Team aufbauen oder sind vielleicht sogar schon dabei? Egal, was Sie vorhaben:
epicinsights hilft Ihnen mit hochspezialisierten Consultants und vielen Jahren Projekt-Erfahrung. Mit einem umfassenden Tech-Stack und unserer eigenen Big Data-Infrastruktur realisieren wir für Sie maßgeschneiderte Data-Lösung und unterstützen Sie auch beim Aufbau datenzentrierter inhouse Teams und Anwendungen.